Wie im vorigen Kapitel gelernt ist fetch die Methode um asynchrone HTTP Requests
zu machen. Mit fetch kann man Webseiten verbessern – man kann sie aber
auch verschlechtern.
fetch statt Links - die Idee
Stellen dir vor du haat eine Website mit 5 statischen HTML-Seiten, die
durch einfache Links verbunden sind.
Demo Seite
Wenn man fetch kennen lernt, kommt man vielleicht
auf die Idee: statt normaler Links lädt man die neue Seite nur noch mit fetch und ersetzt dann den Inhalt der aktuellen Seite. Was spricht dafür?
- Keine Code-Wiederholung: head, footer muss nur einmal, in der erste Seite, gespeichert werden
- die einzelnen Seite wir kleiner, das Laden der Seite vielleicht schneller
- es entfällt das erneute checken/laden von CSS und Javascript Ressourcen.
Beispiel
Nun surfen wir durch diese Site und beobachten in den Developer Tools welche http-Requests
gemacht werden: Demo Seite
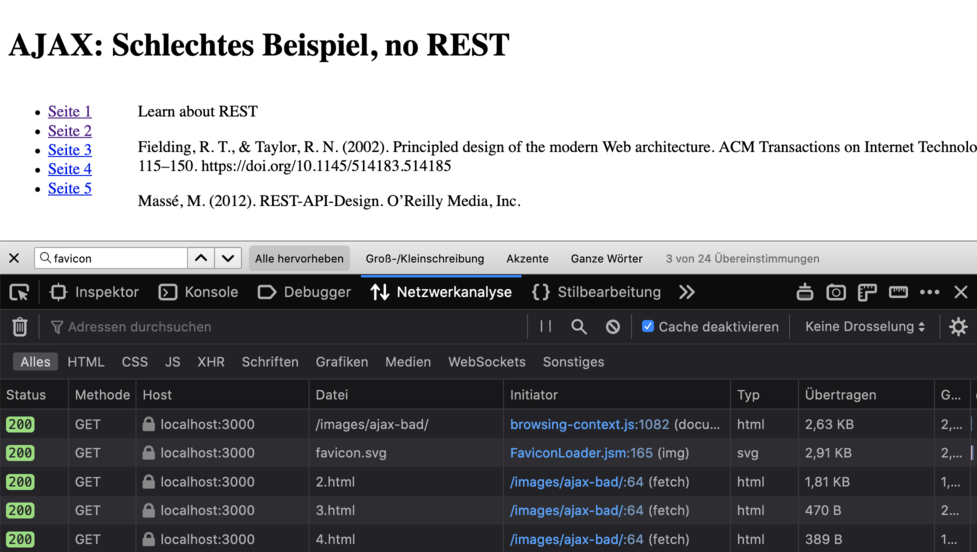
Beim Anklicken des „Links“ wird jeweils ein GET
Request abgesetzt. Aber: die URL in der Adresszeile des Browsers bleibt immer
gleich. Keine der „Seiten“ hat eine eigene URL.
Keine URL, viele Probleme
Das hat viele Auswirkungen, unter anderem:
- Man kann keinen Link zu einer bestimmten Seite setzen – nur zur „Startseite“
- Man kann kein Lesezeichen (Bookmark, Favoriten) auf eine bestimmte Seite setzen
- Google „sieht“ den Text der einzelnen Seite zwar, aber kann immer nur auf das Deckblatt verweisen.
Vergleicht man Vor- und Nachteile sieht man schnell, dass in diesem Fall die
Version ohne fetch (ganz normale Links) besser wäre.
Single Page Apps
Um das Problem der “fehlendes URLs” zu lösen gibt es in der
“History API” die Methoden pushState und replaceState.
Damit kann man für die verschiedenen Zustände innerhalb eines
HTML Dokuments jeweils eine URL definieren. Damit funktionieren das
verlinken, Lesezeichen setzen, u.s.w. wieder.
Webseite die Javascript und pushState in dieser Weise nutzen nennt
man “Single Page Apps” (SPA).
/
#