Für diese Lehrbuch ist eine technische Sicht auf das World Wide Web die relevante.
Am Ende dieses Kapitels kommen wir zu so einer technisches Definition.
Aber zuerst beginnen wir mit ein paar allgemein bekannten Fachwörtern:
Das Internet
Das Internet ist ein Zusammenschluss von Computernetzwerken zu einem weltweiten Verbund.
Nach ersten technischen Versuchen in den 1970er Jahren
wurden in den 1980er Jahren zunächst Computer an US-amerikanischen Hochschulen angeschlossen.
Anschließend wurden auch Hochschulen weltweit angeschlossen.
Ab Anfang der 1990er Jahre erhielten auch andere Organisationen, Firmen und Privatpersonen
Zugang. 2025 haben weltweit mehr als die Hälfte aller Menschen Zugang zum Internet.
Der Internetzugang eröffnet viele Möglichkeiten: das Versenden von E-Mails oder Nachrichten,
Audio- und Video-Streaming, Online-Games und eben auch das Web.
Webbrowser
Ein Webbrowser, oder kurz Browser, ist ein Programm, das Informationen aus dem Internet lädt
und anzeigt.
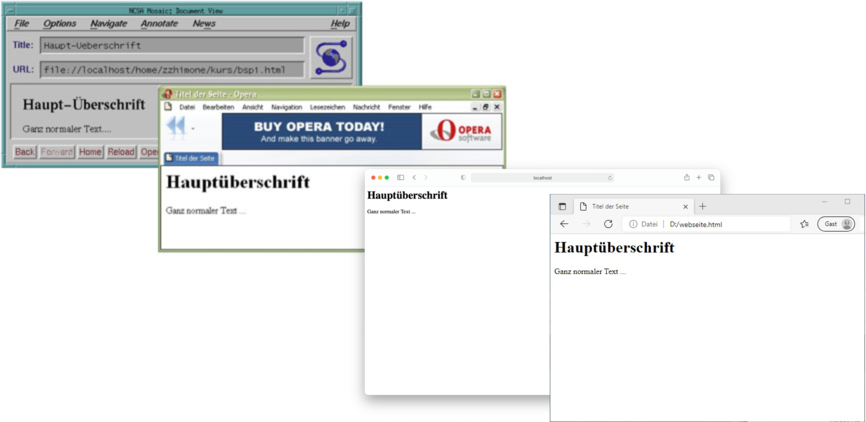
Es gibt sehr viele verschiedene Webbrowser. Die folgende Abbildung zeigt vier davon: den Browser
„Mosaic“ , der im Jahre 1993 als zweiter Webbrowser
mit grafischer Oberflächen stark zur Verbreitung des World Wide Web beigetragen hat, und
die Browser Opera, Firefox und Chrome (in Versionen aus verschiedenen Jahren).
Alle eben erwähnten Browser haben gemeinsam, dass sie auf einem Computer mit Monitor oder
einem Laptope eingesetzt werden.
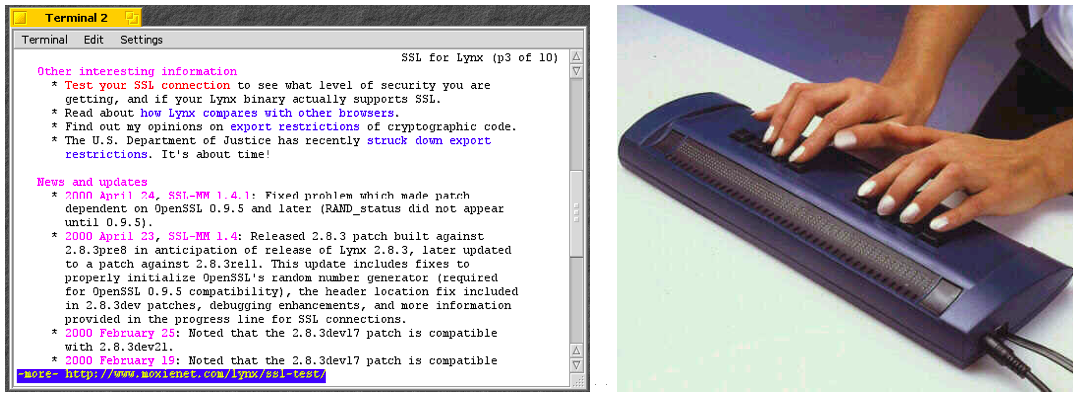
Es gibt aber auch „exotischere“ Browser. Die nächste Abbildung zeigt den Browser Lynx, der nur Text, aber keine Bilder darstellt. Daneben sehen Sie eine […]
Die „Braille-Ausgabezeile“ ist ein Gerät, das eine Zeile Text in Blindenschrift übersetzt. Dieses Gerät wird heute kaum noch benutzt. Stattdessen wird die Anzeige des Computers von einer AI-Stimme vorgelesen.
Seit ca 2017 werden mehr Webbrowser auf Smartphones als Webbrowser auf Computern benutzt. Achtung: das Diagramm
zeigt den Anteil, die absolute Zahl ist gestiegen.
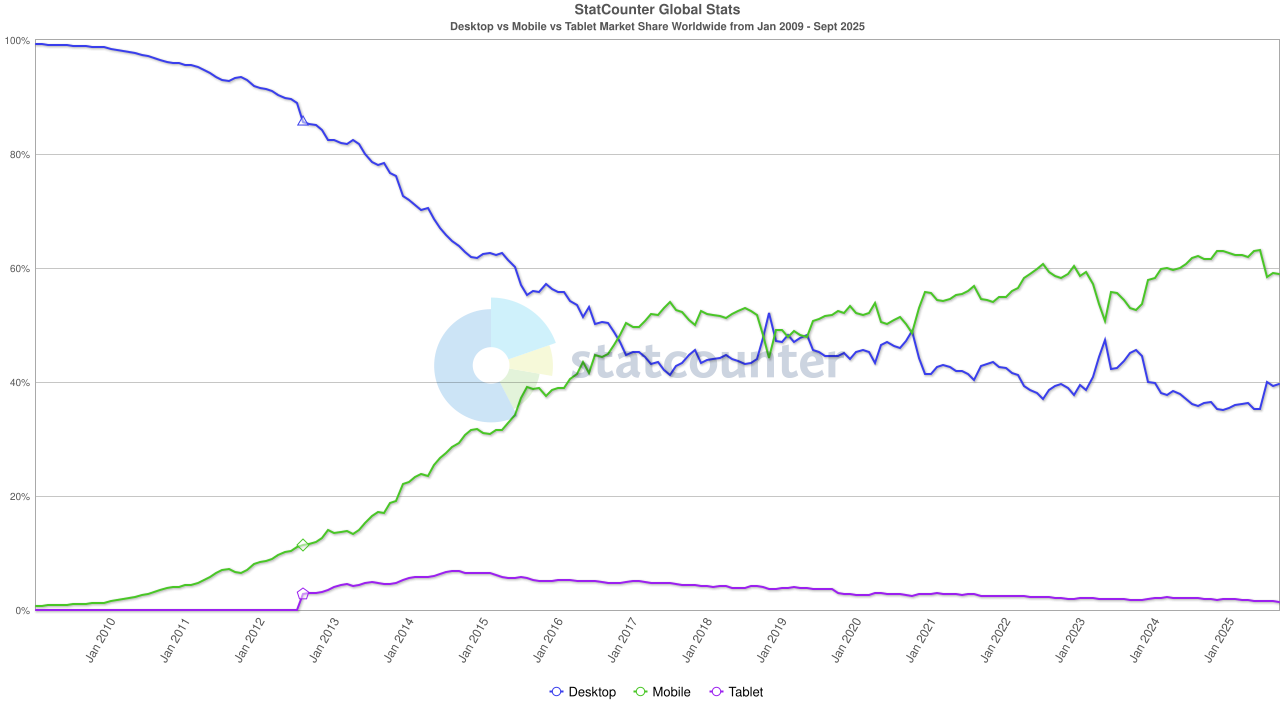
Statistik von StatsCounter
Auch auf Android-Smartphones gibt es die verschiedenen Browser: Chrome, Firefox, … Auf iPhones gibt
ein Monopol für Safari: Es gibt zwar andere Browser, aber sie müssen alle dieselbe Software für
die Darstellung, die “Rendering Engine” verwenden. (Stand Sommer 2025)

Webseite
Die Dokumente, die im Webbrowser dargestellt werden nennt man Webseiten.
Eine Webseite kann – im Gegensatz zu einer Seite in einem Buch – beliebig lang sein. Ist
die Seite zu groß / zu lang für das Browser-Fenster, dann erscheint ein Scrollbalken
mit dem man den Rest der Seite erreichen kann, wie in der nächsten Abbildung gezeigt.
Website
Eine Webseite ist also ein Dokument. Verwechseln Sie diesen Begriff nicht mit
dem englischen Wort Website. Eine Website besteht aus mehreren
Webseiten, die zusammen gehören und untereinander verlinkt sind.
Achtung: es gibt kein Wort Webside.

Webseite und HTML
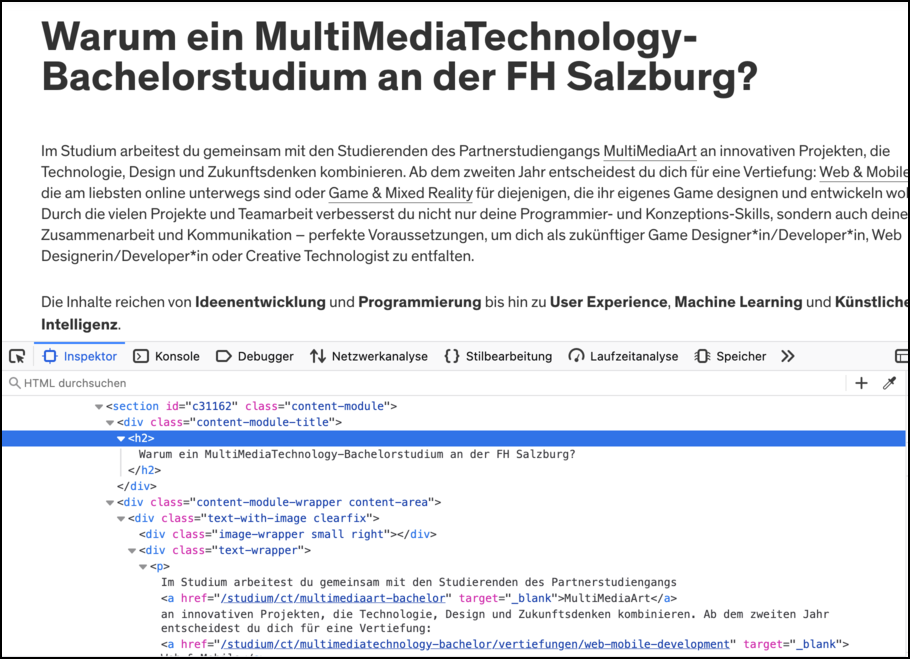
Eine Webseite besteht in erste Linie aus HTML-Code. Den Code kann man
in jedem Browser sehen, wenn man die “Developer Tools” öffnet, mit der Taste F12,
oder mit Ctrl+Shift+I oder Command+Option+I (auf Mac):
In diesem Bild sieht man einen Teil einer Webseite, und darunter, in den
Developer Tools, den entsprechenden HTML Code:
Webserver
Als Webserver bezeichnet man entweder den ganzen Computer,
oder speziell nur die Software, die eine Webseite liefert.
Es gibt zwei Open Source Projekte die
meist als Webserver verwendet werden und auf allen
Betriebssystemen laufen:
- Apache Webserver (“a patchy webserver”)
- nginx (“Engine X”)

URL
Eine URL ist die Adresse einer Webseite. Ein einfaches Beispiel:
https://www.fh-salzburg.ac.at/studium/ct/multimediatechnology-bachelor#c5164
Diese URL zerfällt in 4 Teile:
https Dieser erste Teil wird als “Schema” berzeichnet. hier wird Übertragungsprotokoll HTTP in der verschlüsselten Variante (S) angegeben
www.fh-salzburg.ac.at der Webserver
/studium/ct/multimediatechnology-bachelor wird vom Webserver interpretiert, meist eine Pfad-Angabe. In diesem Fall aber nicht, da die Seite von einem Content-Management-System (TYPO3) erstellt wird.
c5164 Textmarke innerhalb des Dokuments – wird vom Browser interpretiert wenn das Dokument dargestellt wird
Eine URL mit Parametern:
https://www.google.com/search?q=schokolade&ie=utf-8&oe=utf-8
Mit den Fragezeichen, dem kaufmännischen Und und dem Ist-Gleich-Zeichen werden hier Parameter
an die URL angefügt.
| Parameter |
Wert |
| q |
schokolade |
| ie |
utf-8 |
| oe |
utf-8 |
HTTP ist nicht das einzig mögliche Schema, hier ein paar weitere Beispiele:
- mailto:brigitte.jellinek@example.com
- tel:+1-816-555-1212
- javascript:alert(‘Hallo’)
- data:image/svg+xml,%3csvg xmlns=’http://www.w3.org/2000/svg’ viewBox=’0 0 50 50’
%3e%3cpath d=’M22 38V51L32 32l19-19v12C44 26 43 10 38 0 52 15 49 39 22 38z’/%3e
%3c/svg%3e
Das war nur eine informelle Darstellung der Syntax einer URL. Die ganze Wahrheit
findest du im Dokument RFC 1738.
Client und Server
Die Begriffe Client und Server werden in einem Computernetzwerk verwendet,
wenn zwei Computer mit unterschiedlichen Rollen miteinander Daten austauschen.
- Ein Server ist ein Computer der einen bestimmten Dienst anbietet,
- ein Client ist der „Kunde“, also der Computer der den Dienst in Anspruch nimmt.
Nach diesem Prinzip funktionieren Web, E-Mail, SFTP:
| Dienst |
Client |
Server |
| Web |
Webbrowser - lädt Webseiten vom Server und stellt sie dar |
Webserver – liefert auf Anfrage die Webseiten |
| E-Mail |
E-Mail Programm (nicht webmail!) – lädt E-Mails vom Server, zeigt sie an, kann neue E-Mails an einen Server schicken der sie zustellt, … |
Mailserver – speichert E-Mail in verschiedenen Postfächern, leitet E- Mail weiter (an den Server der Empfänger*in) |
| SFTP |
SFTP-Client – lädt Dateien (verlüsselt) von einem Server herunter oder auf einen Server hinauf |
SFTP-Server – speichert Dateien |
Eine Alternative Arbeitsteilung zu Client/Server ist Peer-zu-Peer. Dabei sind alle
beteiligten Computer gleichberechtigt, es gibt keine verschiedenen Rollen. Nach diesem
Prinzip funktionieren Datei-Tauschbörsen wie eDonkey.
HTTP
Das Hypertext Transfer Protocol ist ein
relativ simples Protokoll in einem Computernetzwerk. Alle
Aktivität wird vom Client (=Browser) initiiert. In der einfachsten Form sieht
HTTP so aus (hier 9 Schritte am Beispiel der URL https://www.fh-salzburg.ac.at/studium/ct/multimediatechnology-bachelor#c5164
- Eine URL wird in den Browser eingetippt, oder ein Link wird im Browser angeklickt
- Der Browser analysiert die URL und ermittelt daraus den Domain Namen des Webservers (
www.fh-salzburg.ac.at), löst diese über DNS zur IP-Adresse auf, das Ergebnis lautet 193.170.193.57
- Der Browser baut eine TCP-Verbindung zu
193.170.193.57, Port 443 auf
- Er sendet einen HTTP-Request:
GET /studium/ct/multimediatechnology-bachelor HTTP/1.0\n\n
- Der Webserver nimmt die Anfrage entgegen und analysiert sie. Meistens interpretiert er sie als Aufforderung, eine bestimmte Datei von der Platte zu lesen. In diesem Fall aber wird ein PHP Programm gestartet, dass Daten aus einer Datenbank abfragt und als HTML aufbereitet.
- Der Webserver schickt einen HTTP-Response an den Browser, diese enthält einen Statuscode, z. B.
200 OK, einige Zusatzinformationen und dann die eigentlichen Daten der Webseite als HTML
- Der Browser nimmt das Dokument in Empfang und stellt es dar
- Der Browser scrollt das Dokument bis zur Textmarke
c5164
- Der Browser beendet die TCP-Verbindung
Das war ein sehr einfachs Beispiel, wie das Protokoll ablaufen kann.
Einen tieferen Einblick in HTTP erhalten Sie im Kapitel http.
Was ist das Web - aus technischer Sicht
Das World Wide Web ist also ein verteiltes (Client/Server) Informationssystem,
das durch folgende drei Standards definiert wird:
Webbrowser und Webserver können jederzeit neu geschreiben werden, sie müssen sich nur
an die Standards halten.
/
#